ChangKun的Modern C++学习教程笔记
一、概述
本教程来源于欧长坤的Modern C++教程页面。教程中作者是使用make来进行编译的。我这里采用了一种更复杂的方法:利用windows系统的WSL2作为运行环境,使用Visual Studio作为IDE,使用cmake来进行编译。当然其实也可以使用VS Code可能更加灵活通用。但是想增强对VS的了解。另一方面我使用了Codeium作为代码编写助手,因此禁用了自带的IntelliSense功能。具体可以看1.1节的环境配置部分。
1.1、环境配置
我假定你使用的是windows 11(理论上Windows 10也可以,但我没有测试过)。我假定你也安装了Visual Studio 2022。如果你没有安装,可以到微软官网下载安装。除了常规的Visual Studio安装,你还需要安装WSL2。我安装的是debian 12。当然其它版本也是可以的,只是后面的过程你可能需要根据自己的发行版本进行相应调整。
1.1.1 在Visual Studio中启用clang
具体过程可参考微软官方文档.
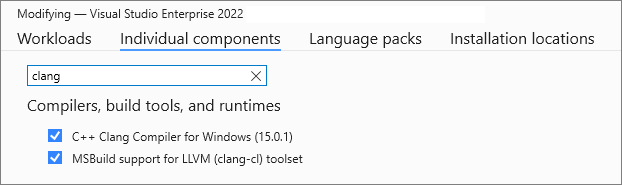
基本步骤就是在individual component中安装Clang Compiler for Windows和clang-cl。
1.1.2 在wsl2中安装llvm
这一部分可以参照我的一篇博客。
TODO: 稍后给出链接。
1.1.3 安装Codeium并关闭IntelliSense
打开扩展>管理扩展,搜索codeium并安装。codeium需要注册,具体过程请自行搜索。
1.1.4 在wsl2中安装ssh和其它必须的软件
TODO: 稍后提供方法
1.1.5 开启ssh服务并尝试从vs中连接wsl2
TODO: 稍后提供方法
1.1.6 制作一个hello world项目并测试
TODO: 稍后提供方法
二、教程第二章笔记:语言可用性的强化
第二章的标题是“语言可用性的强化”。这里的“语言可用性”是指发生在运行时之前的语言特性。
2.1 常量
2.1.1 空指针
空指针:nullptr。在空指针这一部分程序提供了一段测试代码,其中用到了type_traits。这个库定义了一系列与类型(Type)相关的模板和函数。本次使用的is_same模板类正是这个头文件中的函数,可以用来判断两个类型是否相同。另外需要说明的是nullptr的类型是std::nullptr_t。Modern C++建议使用std::is_same来比较两个类型是否相同。
2.1.2 常量表达式标签
常量表达式标签:constexpr。尽管之前的c++已经有常量表达式,但是Modern C++提供了更强大的constexpr用来在编译时优化这些常量表达式。关键字constexpr是在C++11中引入的,并在 C++14中进行了改进。它表示constant(常数)表达式。与const一样,它可以应用于变量:如果任何代码试图modify(修改)该值,将引发编译器错误。与const不同,constexpr也可以应用于函数和类constructor(构造函数)。constexpr指示值或返回值是constant(常数),如果可能,将在编译时进行计算。本教程对于constexpr的描述不太清晰,建议看微软关于constexpr的描述.
2.2 变量及其初始化
2.2.1 if/switch变量声明强化
if/switch变量声明强化:在if和switch语句中可以声明一个临时变量。这方便迭代器等算法的实现。这以增强功能在C++17才引进。在示例程序中用到了std::find定义在algorithm头文件中。用来在某个范围内搜寻目标变量的第一次出现的位置。函数原型可参考这里.
2.2.2 初始化列表
初始化列表:用在对象初始化时使用。在传统C++中,不同对象有不同的初始化方法。比如普通数组,POD(Plain Old Data)类型可以使用{}初始化,而类对象则需要使用构造函数(拷贝构造或()运算符)。不同的类型初始化方法不同。而Modern C++中引入了初始化列表,可以统一初始化语法。在c++11中首选引入了std::initializer_list,它是一个模板类,用来将类初始化。此外C++11还提供了统一的语法来初始化任意对象。
2.2.2 结构化绑定
结构化绑定:结构化绑定提供了类似其他语言中提供的多返回值功能。在C++11/14中只能通过std::tuple和std::tie来变相实现多返回值功能。但是我们依然需要非常清楚元组包含了多少个对象以及各自的类型。C++17引入了结构化绑定功能,大大提升了多返回值编写的体验。
2.3 类型推导
文章认为在传统C和C++中,参数的类型必须明确定义,这其实对于快速编码没有帮助。尤其面对一大堆复杂的模板类型时,必须明确指出变量类型才能进行后续的编码,这不仅拖慢开发效率。代码还变得又臭又长。(也增加了错误的发生概率。尽管如此我自己认为数据类型还是很重要的。尤其对于底层的编程,数据的类型和数据的存储和处理都非常重要。)
C++引入了auto和decltype关键字来解决这个问题。
2.3.1 auto关键字
auto:auto关键字很早就进入了C++,但时钟作为一个存储类型的指示符存在,与register并存。(另外传统C++使用关键字register指示将变量存储在register中。但是现在的编译器可以比人工提供更优的存储方式,因此在Modern C++中register关键字也被弃用。)在传统C++中如果一个变量不是register,就自动视作auto变量。在C++17中将register的功能弃用,只作为一个保留关键字。auto的语义也随之而来做出变更。在前面的迭代器示例中,就用到了auto。另外复杂的模板类型推导也可以用到auto。从C++20其auto甚至能用于函数传参。(也就是C++11/14/17不能这样做。很多程序目前还在使用C++17及其以前的版本。)但是auto目前还不能推导数组元素类型。实际测试发现参数的返回类型也可以是auto的。比如:
auto sub(auto x, auto y) {
return x - y;
}
auto只能对变量进行类型推导。
2.3.2 decltype关键字
decltype: decltype关键字可以认为是declare type的缩写。这个关键字是为了解决auto关键字只能对变量进行类型推导的缺陷二出现的。它的用法和typeof类似。用法是:decltype(expression)。decltype的作用是返回expression的类型。decltype的表达式一般是变量、函数调用、成员访问、运算符表达式等。decltype的返回值是一个类型,而不是表达式的值。
-
关于
typedef: 早期的C++标准中并没有提供名为typedef的关键字,而是在某些编译器或语言中支持的扩展。在标准C++中,类型推导是通过decltype来实现的,因此可以将typedef视为一种扩展,而不是正式的C++标准关键字。 -
关于
typeid: typeid关键字是用来获取表达式的类型信息的。但是在C++11中,typeid只能用于指针、引用、成员指针、成员函数指针等。在C++17中,typeid可以用于任意表达式。typeid是一个运算符不是函数。typeid 的结果是 const type_info&。 该值是对表示 type-id 或 expression 的类型的 type_info 对象的引用,具体取决于所使用的 typeid 的形式。关于typeid的更多信息,可以参考微软关于typeid的介绍。
2.3.3 尾返回类型
尾返回类型: trailing return type(尾返回类型)是C++11引入的新特性。它允许函数的返回类型在函数声明和定义中分离。在函数声明中,可以指定返回类型,而在函数定义中,可以省略返回类型。这样可以提高代码的可读性。在C++17中,尾返回类型可以用于函数模板。形如decltype(x+y) add(T x, U y)的语句不能通过编译。这是因为编译器读到decltype(x+y)时,并不知道x和y的类型。但是在尾返回类型中,可以将decltype(x+y)作为函数的返回类型。做法如下:
template<typename T, typename U>
auto add(T x, U y) -> decltype(x+y) {
return x + y;
}
从C++14开始可以让普通函数也就被返回值推导,因此下面的写法变得合理:
template<typename T, typename U>
auto add(T x, U y) {
return x + y;
}
#### 2.3.4 decltype(auto) decltype(auto) : 是c++14引入的一个略微复杂的用法。主要用来对转发函数或者封装的返回类型进行推导。它使得我们无需显示的指定decltype的参数表达式。
2.4 控制流
2.4.1 if constexpr
if constexpr: C++17引入了if constexpr来支持在编译时进行条件判断。(原文介绍说是从C++11引入,但是搜索之后发现是C++17引入的。)if constexpr的语法和if语句类似,但是在判断条件前面加上constexpr关键字。这样可以避免运行时判断,提高效率。微软关于if constexpr的介绍也非常有用。关于这条语句可能存在误解,认为是不是用if指示效率低而已?微软教程中举得示例带代码:
// Compile with /std:c++17
#include <iostream>
template<typename T>
auto Show(T t)
{
if (std::is_pointer_v<T>) // Show(a) results in compiler error for return *t. Show(b) results in compiler error for return t.
//if constexpr (std::is_pointer_v<T>) // This statement goes away for Show(a)
{
return *t;
}
else
{
return t;
}
}
int main()
{
int a = 42;
int* pB = &a;
std::cout << Show(a) << "\n"; // prints "42"
std::cout << Show(pB) << "\n"; // prints "42"
}
如果如图使用if而不是if constexpr, 会出现编译错误。原因是当参数类型是int等类型,编译器照例会编译所有的代码语句。
2.4.2 基于范围的for循环
区间for迭代:C++11引入了range-based for循环,终于实现了类似与python那样简洁的代码。关于基于范围的for迭代可参见微软关于range-based for的介绍.基本语法是for (for-range-declaration:expression). 请注意,在语句的 for-range-declaration 部分中,auto 关键字是首选的。如果你看微软的相关章节会发现const auto&这样的写法,这是因为在C++17中,const auto&可以用来声明一个常量引用。也需要明确一点形如for(auto y: x)的写法并不会修改x的值。如果需要修改x的值应该使用形如for(auto& y: x)使用引用的写法。
2.5 模板
C++ 的模板是这门语言的一种特殊的艺术。模板的哲学在于将一切能够在编译期处理的问题丢到编译期进行处理,仅在运行时处理那些最核心的动态服务,进而大幅优化运行期的性能。
2.5.1 外部模板
传统C++中,模板只有在使用时才会被编译器实例化。但是主要每个编译单元(文件)中编译的代码遇到了完整定义的模板,都会被实例化。这就产生了重复实例化的问题。这个问题导致了编译时间的增加。为此Modern C++引入了外部模板,扩充了原来的强制编译器实例化模板的语法,使得我们能够显式的通知编译器何时进行模板的实例化。(其实就是添加extern关键字。)示例如下:
template class std::vector<bool>; // 显式(强制)实例化
extern template class std::vector<double>; // 不再改当前编辑文件中实例化模板
关于模板的详细指示可以查看微软关于模板的介绍.
模板类中的尖括号”>”要特别注意。在传统C++中,可以强制在嵌套模板的两个>之间添加空格,否则会出错。但是从C++11开始,连续的右尖括号>将是被允许的。
2.5.2 类型别名模板
C++中类型(Type)和模板(Template)是两个完全不同单容易混淆的东西。”模板”是一种代码的组织工具,用于生成特定类型或值的代码实例,而”类型”是数据的抽象分类,用于指定数据的内部表示和操作方式。”模板”指的是一种通用的代码框架,它可以用一个或多个类型或值作为参数,在编译时被实例化为特定的类、函数或其他代码实体。在传统C++中,可以使用typedef来定义一个类型,但是去不能用它来定义一个模板。
2.5.3 变长参数模板
在传统C++中,无论是类模板还是函数模板都只能接收股东数量的模板参数;但在C++11中加入了新的表示方法: 允许任意个数、任意类别的模板参数,同事也不需要在定时将参数个数固定。这就是变长参数模板。形式大体如下:
// 变长函数模板
template<typename... Args>
void foo(Args... args) {
// do something with args
}
foo(1, 2.0, "hello"); // 调用foo函数,传入三个参数
// 变长类模板
template<typename... Args>
class Magic <>{
// do something with args
};
class Magic<int, double, std::string> m; // 实例化Magic类模板,传入三个参数
// 甚至可以是0个模板参数
class Magic<> m2; // 实例化Magic类模板,没有参数
// 若要避免0个模板参数的歧义,可以先定义一个模板参数:
template<typename T, typename... Args>
class Magic_2 {
// do something with args
};
class Magic_2<int> m3; // 这样就限制了模板至少有一个参数
函数也可以类似定义
template<typename... Args>
void print(const std::string& s, Args... args);
print("hello", 1, 2.0); // 调用print函数,传入两个参数
template<typename... Args>
auto func_args_num(Args... args) {
auto n = sizeof...(args); // 计算参数个数
return n;
}
但是对于变长参数模板的展开到目前为止仍然没有一种简单的方法。目前有两种方式:
-
递归模板函数法:通过递归调用模板函数,将参数分解为多个参数,直到终止递归的函数。在C++17之前,递归模板方式一般要定义两个函数,其中一个负责展开终止递归函数,另一个负责展开剩余参数。非常繁琐。自C++17以后,可通过利用
if constexpr和sizeof...来实现对终止递归函数的条件编译。这样就只需要定义一个函数。事实上我们尽管使用了变参模板,却不一定需要对参数做逐个遍历,可以利用std::bind及完美转发等特性实现对函数和参数的兵丁,从而达到成功调用的目的。 -
初始化列表展开法:这种方法利用了初始化列表(std::initializer_list)和lambda表达式。语法比较费解,如下:
template<typename T, typename... Args>
void my_printf(T value, Args... args) {
std::cout << value << std::endl;
(void) std::initializer_list<T> {
([&args]{std::cout << args << std::endl;}(),value)...
};
}
除此之外,C++17中还将变长参数的特性带给了表达式:
template<typename... Args>
auto sum(Args... args) {
return (args +...); // 表达式模板
}
int main() {
std::cout << sum(1, 2, 3, 4, 5) << std::endl; // 输出15
return 0;
}
可以看到通过这种方式让迭代操作变得非常简单。
2.5.4 非类型模板参数
类型模板传入的是具体类型,例如:
template<typename T, typename U>
auto add(T a, U b) {
return a + b;
}
而非类型模板参数传入的是可以是变量、表达式、函数调用等,例如:
template<typename T, int N>
void print_array(T (&arr)[N]) {
for (int i = 0; i < N; ++i) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
}
2.6 面向对象
2.6.1 委托构造
C++11引入了委托构造,可以将构造函数委托给另一个构造函数,从而简化构造函数的编写。
2.6.2 继承构造
C++11引入了继承构造,可以继承父类的构造函数,从而简化子类的构造函数编写。
2.6.3 显式虚函数重载
在传统C++中经常容易发生意外重载虚函数的事情。或者当虚函数在基类中删除之后,子类拥有的旧的函数就不再重载此虚函数,而变成了一个普通类方法。这可能造成灾难性的后果。
C++11引入了override和final关键字,可以显式的指示编译器对虚函数进行重载。override关键字用于指示编译器检查函数签名是否正确,final关键字用于指示编译器不再对此函数进行重载。
override: 重载虚函数时,使用override显式的告知编译器进行重载。编译器将检查基函数是否存在与要重载的目标函数一致的虚函数。如果不存在将无法编译。示例如下: ```cpp struct Base { virtual void foo(int); };
struct SubClass : Base { virtual void foo(int) override {/do something/}; // 合法 virtual void foo(float) override {/do something/}; // 非法,签名不匹配 };
* `final`: `final`则是为了防止类被继续继承以及终止虚函数继续重载引入的。声明函数为`final`时,编译器将不再对此函数进行重载。示例如下:
```cpp
struct Base {
virtual void foo() final;
};
struct SubClass1 final : Base {}; // 合法,子类声明为final
struct subClass2 : subClass1 {}; // 非法,子类声明为final
struct SubClass3 : Base {
virtual void foo() override {/*do something*/}; // 非法,父类中声明为final
};
2.6.4 显式禁用默认函数
在传统C++中,如果程序员没有提供,编译器会默认为对象生成默认构造函数、析构函数、复制构造和赋值运算符。另外C++也定义了诸如new delete这样的运算符。当程序员有需要时,可以重载这部分函数。用户想要精确控制默认函数行为一般需要将不需要的函数声明为private。而且用户默认的构造函数和用户定义的构造函数不可以共存。C++11引入了更强大的功能,允许显式的声明采用或者拒绝构造函数。例如:
class MyClass {
public:
MyClass() = default; // 采用默认构造函数
MyClass& operator=(const MyClass&) = delete; // 拒绝复制构造函数
MyClass(int x) : data(x) {} // 定义构造函数
};
2.6.5 强类型枚举
C++11引入了枚举类(enumeration class),并使用enum class语法进行声明。文中提到传统的C++中枚举类型不是类型安全的。两个不同的枚举类型可直接进行比较。同一个命名空间内两个不同模具类型的枚举值不能重名。C++11中使用enum class可以解决这些问题。枚举类用法示例:
enum class Color : unsigned char{ RED, GREEN, BLUE };
文中给出了一段很费解的代码:
#include <iostream>
template<typename T>
std::ostream& operator<<(
typename std::enable_if<std::is_enum<T>::value,
std::ostream>::type& stream, const T& e)
{
return stream << static_cast<typename std::underlying_type<T>::type>(e);
}
2.7 习题解答
2.7.1 第一题
- 问题: 使用结构化绑定,仅用一行函数内代码实现如下函数:
template <typename Key, typename Value, typename F> void update(std::map<Key, Value>& m, F foo) { // TODO: } int main() { std::map<std::string, long long int> m { {“a”, 1}, {“b”, 2}, {“c”, 3} }; update(m, { return std::hash<std::string>{}(key); }); for (auto&& [key, value] : m) std::cout « key « ”:” « value « std::endl; }
- 解答:
本题的难点即使不是答案,而是问题本身。问题本身的语法有很多关键点。
std::map<Key, Value>,std::hash和lambda表达式这三个语法点还是要理解一下的。问题的简单描述其实应该是如何在update函数中添加一行代码,实现用hash值取代每个key原有的value。for (auto&& [key, value] : m) value = foo(key);答案也很简单,就是将value用foo函数的计算结果代替。foo函数在main函数中传入,用来返回一个hack code。答案的另一个重点是
auto&& [key, value] : m,这里用了两个&,而不是一个。这是因为不但需要对键值对解引用,还需要能够修改值。
2.7.2 第二题
- 问题: 尝试用折叠表达式实现用于计算均值的函数,传入允许任意参数。
- 答案:这个问题和示例中的求sum类似。指示需要使用
sizeof...,我尝试将sizeof...赋值给一个变量,然后使用if constexpr去判断是否为0。结果发现不能通过编译。正确答案如下(和原来的答案稍有出入): ```cpp #include#include
template<typename … Ts> auto average(Ts … args) { if constexpr (sizeof…(args) > 0) { return ((args + …) / sizeof…(args)); } else { return 0; } }
int main() { std::cout « average(1, 2, 3, 4, 5, 7, 8) « std::endl; // 3 return 0; }
## 三、教程第三章笔记:语言运行期的强化
教程第三章的标题是《语言运行期的强化》。它主要讲解了modern C++在运行期的一些优化。
### 3.1 Lambda表达式
现代语言比如python,rust之类都有lambda表达式。C++11引入了lambda表达式,可以用来创建匿名函数。lambda表达式可以捕获外部变量,也可以作为函数参数。lambda表达式的语法如下:
```cpp
[capture](parameters) mutable(optional) -> return-type { function-body }
其中,capture可以捕获列表;parameters表示函数的参数;mutable表示函数是否可以修改捕获的变量,可选;return-type表示函数的返回类型,使用的是我们之前描述的尾返回类型。这里重点讲一下捕获列表[capture]。捕获列表可以理解未parameter的一种类型。Lambda表达式内部函数体默认情况下式不能够使用函数体外部的变量的,这时候捕获列表就可以起到传递外部数据的作用。捕获列表有四种形式:值(value)捕获、引用(reference)捕获、隐式捕获、表达式捕获。
- 值捕获:与参数传值类似(值捕获的前提式变量可以拷贝)。被捕获的变量在Lambda表达式被创建时拷贝,而非调用时才拷贝。示例如下:
void lambda_value_capture() { int value = 1; auto copy_value = [value] { return value; }; value = 100; auto stored_value = copy_value(); std::cout << "stored_value = " << stored_value << std::endl; // 这时, stored_value == 1, 而 value == 100. // 因为 copy_value 在创建时就保存了一份 value 的拷贝 }上面的代码示例中请注意没有用std::cout直接输出copy_value的值。这是因为copy_value实际是一个函数对象,调用它不会执行函数体,而是返回一个类似函数指针一样的东西。后面的文章这样描述:”Lambda 表达式的本质是一个和函数对象类型相似的类类型(称为闭包类型)的对象(称为闭包对象), 当 Lambda 表达式的捕获列表为空时,闭包对象还能够转换为函数指针值进行传递”.
- 引用捕获:与引用传参类似,引用捕获保存的时引用,值会发生变化。可以和值捕获做个比较。示例如下:
void lambda_reference_capture() { int value = 1; auto copy_value = [&value] { return value; }; value = 100; auto stored_value = copy_value(); std::cout << "stored_value = " << stored_value << std::endl; // 这时, stored_value == 100, value == 100. // 因为 copy_value 保存的是引用 }请注意这里引用捕获使用的符号
&,和普通的参数引用类似。 - 隐式捕获:编译器使用隐式捕获可以自动捕获外部变量。隐式捕获常见有五种形式:
- [] 空捕获列表
- [name1, name2, …] 捕获一系列变量
- [&name1, &name2, …] 捕获一系列变量的引用
- [=] 值捕获列表,让编译器自动推导值捕获列表
- [&] 引用捕获,让编译器自行推导引用列表
但编译器根据什么样的规则自行推导。文章没有讲解。
- 表达式捕获:前面三种形式捕获的均是左值,而不能捕获右值。C++14中引入了表达式捕获功能,使其可以捕获右值。示例如下:
```cpp
#include
#include // std::make_unique #include // std::move
void lambda_expression_capture() {
auto important = std::make_unique
在上面的important式一个独占指针,是不能被`=`运算符捕获的。这时候我们需要使用`std::move`将其转移成右值,在表达式中初始化。
```txt
右值引用是 C++11 引入的新概念,用于表示对临时对象或将要销毁的对象的引用。它在语义上区别于左值引用,可以用于启用移动语义、完美转发以及构造临时对象等操作。右值引用的语法是在类型名称后添加两个连续的 & 符号(&&)。通过声明一个右值引用,可以将其绑定到临时对象或将要销毁的对象,从而在这些对象上执行移动操作,以提高性能并避免不必要的复制。
在C++14之后,lambda表达式也支持auto关键字从而具备了泛型的功能。(Lambda表达式不能能被模板化)示例如下:
auto add = [](auto x, auto y) {
return x+y;
};
add(1, 2); // 3
add(1.0, 2.0); // 3.0
add("hello", "world"); // helloworld
在C++中,“闭包类型”通常指的是lambda表达式(lambda expressions)的类型,而“闭包对象”是指lambda表达式创建的可调用对象(callable object)。Lambda表达式是C++11引入的功能,用于创建匿名函数对象。闭包类型指的是lambda表达式的类型,而闭包对象是指lambda表达式创建的函数对象,可以像函数一样被调用。
3.2 函数对象包装器
文中专门提到这一点“这部分内容虽然属于标准库的一部分,但是从本质上来看,它却增强了 C++ 语言运行时的能力, 这部分内容也相当重要,所以放到这里来进行介绍。” 实际上这部分讲解的内容,是许多初学C++的人所不知道的。
3.2.1 std::function
在文中作者先使用一个example描述了lambda表达式表示的匿名函数分别被作为函数类型和函数被使用。在C++11中,统一了两者的改变:将能够被调用的对象的类型通常为可调用类型。而这种类型可以通过std::function 来表示。文中有这样一段总结:
C++11 std::function 是一种通用、多态的函数封装, 它的实例可以对任何可以调用的目标实体进行存储、复制和调用操作, 它也是对 C++ 中现有的可调用实体的一种类型安全的包裹(相对来说,函数指针的调用不是类型安全的), 换句话说,就是函数的容器。当我们有了函数的容器之后便能够更加方便的将函数、函数指针作为对象进行处理。
或者有稍微清晰一点的描述:
std::function是C++标准库中的一个模板类,用于封装可调用对象,例如函数、函数指针、成员函数指针或者lambda表达式。它提供了一种通用的方式来存储、传递和调用任意可调用对象,从而使得代码更加灵活、可复用和可扩展。
听着像是互联网黑话。基本上可以归纳为“通用”,“安全”和“灵活”。其实最好的理解方式还是看代码。请注意std::function的头文件是<functional>。
3.2.2 std::bind和std::placeholders
std::bind 是 C++ 标准库中的一个函数,它用于创建一个函数对象,这个函数对象可以将原始函数的参数绑定到特定的数值上。std::placeholders 是 C++ 标准库中用于占位符的命名空间,它提供了一系列预定义的占位符,用于在使用函数对象时指定需要绑定的参数位置。我们可以使用 std::placeholders::_1, std::placeholders::_2, std::placeholders::_3, … 以此类推,来指定绑定参数列表中对应的位置。
3.2.3 右值引用
在前面讲解lambda表达式的时候,我已经替代过右值引用。但是通过那段描述。还是挺晕的。这一段作者对右值引用做了详细说明:
右值引用是 C++11 引入的与 Lambda 表达式齐名的重要特性之一。它的引入解决了 C++ 中大量的历史遗留问题, 消除了诸如 std::vector、std::string 之类的额外开销, 也才使得函数对象容器 std::function 成为了可能。
文中对涉及的几个名词做了专门的解释,确实让人有所领悟:
- 左值 (lvalue, left value): 顾名思义就是赋值符号左边的值。准确来说, 左值是表达式(不一定是赋值表达式)后依然存在的持久对象。
- 右值 (rvalue, right value): 右边的值,是指表达式结束后就不再存在的临时对象。请注意右值要么是一个纯右值,要么是一个将亡值。
- 字面量 (literal): 字面量就是直接写在代码中的值,例如 10, “hello”, 3.14, true 等。
- 纯右值 (prvalue, pure rvalue): 纯粹的右值,要么是纯粹的字面量,例如 10, true; 要么是求值结果相当于字面量或匿名临时对象,例如 1+2。非引用返回的临时变量、运算表达式产生的临时变量、原始字面量、 Lambda 表达式都属于纯右值。需要注意的是,字面量除了字符串字面量以外,均为纯右值。而字符串字面量是一个左值,类型为 const char 数组。但是注意,数组可以被隐式转换成相对应的指针类型,而转换表达式的结果(如果不是左值引用)则一定是个右值(右值引用为将亡值,否则为纯右值)。这一部分的描述是否费解。在我测试
decltype(101)之类的表达式时,发现也是能编译的。也就是说此时的字面值其实被当作了表达式,从而被转换成了左值? - 将亡值 (xvalue, expiring value): 也是 C++11 为了引入右值引用而提出的概念(因此在传统 C++ 中, 纯右值和右值是同一个概念),也就是即将被销毁、却能够被移动的值。(就是说如果这个值没有被移动就会被销毁?)
在作者进行讲解时,用到了static_cast.这里简单对它进行一些说明。static_cast 是 C++ 中用于执行显式类型转换的操作符。它可以将一个表达式转换为指定的类型,包括用户定义的类型、内置类型和其他类型。static_cast 在编译时执行类型检查,并且通常用于较为安全的类型转换操作。static_cast 是在编译时执行类型转换,不进行运行时检查。它主要用于执行较为安全的类型转换,例如基本类型之间的转换、向上转型或者非多态类的类型转换。static_cast 在执行类型转换时不进行运行时类型检查,因此转换的安全性需要程序员自行确保。而 dynamic_cast 则是在运行时执行类型转换,它可以用于执行安全的向下转型(将指向基类对象的指针或引用转换为指向派生类对象的指针或引用),并进行运行时类型检查,以确保类型转换的安全性。dynamic_cast 只能在存在虚函数的类层次结构中进行类型转换,用来处理多态类型的转换。
在作者进行讲解时,还用到了static_assert. static_assert 是 C++11 引入的关键字,用于在编译时进行静态断言(Static Assertion)。它允许在编译时对某些条件进行检查,如果条件为假,则导致编译失败并显示错误消息。static_assert 的语法形式如下:
static_assert (constant_expression, "error message");
static_assert 只能用于在编译时进行常量表达式的验证,不能用于运行时条件的检查。因此,它适用于那些只需在编译期就能确定的条件检查,例如类型大小的验证、常量的合法性检查等。
要拿到一个将亡值,就需要用到右值引用:T &&,其中 T 是类型。 右值引用的声明让这个临时值的生命周期得以延长、只要变量还活着,那么将亡值将继续存活。C++11 提供了 std::move 这个方法将左值参数无条件的转换为右值, 有了它我们就能够方便的获得一个右值临时对象.
作者举了一段代码:
#include <iostream>
#include <string>
void reference(std::string& str) {
std::cout << "lvalue" << std::endl;
}
void reference(std::string&& str) {
std::cout << "rvalue" << std::endl;
}
int main()
{
std::string lv1 = "string,"; // lv1 is a lvalue
// std::string&& r1 = lv1; // illegal, rvalue can't ref to lvalue
std::string&& rv1 = std::move(lv1); // legal, std::move can convert lvalue to rvalue
std::cout << rv1 << std::endl; // string,
const std::string& lv2 = lv1 + lv1; // legal, const lvalue reference can extend temp variable's lifecycle
// lv2 += "Test"; // illegal, const ref can't be modified
std::cout << lv2 << std::endl; // string,string
std::string&& rv2 = lv1 + lv2; // legal, rvalue ref extend lifecycle
rv2 += "string"; // legal, non-const reference can be modified
std::cout << rv2 << std::endl; // string,string,string,
reference(rv2); // output: lvalue
return 0;
}
这段代码似乎十分简单。但是结果让人很费解。第一’reference(rv2)’为什么使出的是lvalue。其次使用std::move(lv1)将lv1的所有权转移给了rv1.如果再对lv1操作,似乎是对rv1操作了。比如如果我在std::string&& rv1 = std::move(lv1);之后,尝试lv1.assign("newstr1")。这时候rv1的信息也相应的变化了。第三,如果像程序一样使用const std::string& lv2 = lv1 + lv1;是能够编译的。但是如果改成”std::string& lv2 = lv1 + lv1;”就会报错。
请注意上面的代码中lv1和lv1 + lv1的语义有很大的区别。前者是一个现存的变量,后者会生成一个临时变量。临时变量的生命周期很短,而右值引用延长了它的声明周期。
3.2.4 移动语义
作者在“移动语义”这一段编写了一段很有意思的代码,很好的展示了构造、移动、析构和拷贝操作。我的代码的调试输出如下(指针输出一般不同,但流程类似):
construct: @0x55555556aeb0
construct: @0x55555556b2e0
move: @0x55555556b2e0
destruct: @0
destruct: @0x55555556aeb0
obj:
@0x55555556b2e0
Value1
destruct: @0x55555556b2e0
可以看到程序开始在调用return_rvalue函数的时候,先构建了两个临时对象a和b,然后b被move给了obj对象,然后这段程序结束之后程序析构了a和b。但是b因为被move了,此时的地址变成了nullptr。所以析构的时候其实并没有析构b。接着程序按照代码要求输出了obj的地址和值。可以看到,这两个信息和b的信息一致。最后在main函数结束之后。obj的生命周期结束,所以析构了b之前创建的对象。
作者举了第二个关于move的例子。这里将std::string对象的值move给了vector对象的一个元素中。结果之前那个std::string对的内容为空。但是在前面的代码中将lv1move给rv1之后反而里面有内容。规则还是挺奇怪的。
为了便于演示这段奇怪的行为,我们可以编写类似的代码:
#include <iostream>
#include <string>
#include <utility>
#include <vector>
int main(){
std::string str = "str to move";
std::string&& rstr = std::move(str);
std::cout << "str: {" << str ;
std::cout << "} and rstr: {" << rstr << "}"<< std::endl;
std::vector<std::string> v;
v.push_back(std::move(str));
std::cout << "str: {" << str ;
std::cout << "} and rstr: {" << rstr << "}"<< std::endl;
return 0;
}
这段代码的输出如下:
str: {str to move} and rstr: {str to move}
str: {} and rstr: {}
可以看出第一次move之后str和rstr变成了同一个对象。操作str就是操作rstr。但是在push_back之后第二次打印输出的时候,str的内容变成了空,这时候rstr的内容也变成了空。这两次move的奇怪行为还是值得关注的。
为了追查原因,我仿照作者之前的代码做一个自己的类去继承std::string:
#include <iostream>
#include <string>
#include <utility>
#include <vector>
class MyStr : public std::string {
public:
int* ptr;
using std::string::string;
using std::string::operator=;
MyStr() :ptr(new int(1)) {
std::cout << "construct: @" << ptr << std::endl;
}
MyStr(MyStr& s) :ptr(new int(*s.ptr)) {
std::cout << "copy: @" << ptr << std::endl;
}
MyStr(MyStr&& s) :ptr(s.ptr) {
std::cout << "move: @" << ptr << std::endl;
s.ptr = nullptr;
}
~MyStr() {
std::cout << "destruct: @" << ptr << std::endl;
}
};
int main() {
//MyStr str = "str to move";
MyStr str;
str.assign("str to move");
MyStr&& rstr = std::move(str);
std::cout << "str: {" << str;
std::cout << "} and rstr: {" << rstr << "}" << std::endl;
std::vector<MyStr> v;
v.push_back(std::move(str));
std::cout << "str: {" << str;
std::cout << "} and rstr: {" << rstr << "}" << std::endl;
return 0;
}
输出如下:
construct: @0x55555556beb0
str: {str to move} and rstr: {str to move}
move: @0x55555556beb0
str: {str to move} and rstr: {str to move}
destruct: @0x55555556beb0
destruct: @0
可以发现,第一次move并没有真正的被move(第一次打印之前没看到move的输出)。第二次move才真正的move成功。
3.2.5 完美转发
因为在C++11中引入了右值,导致了引用塌陷问题。所以C++11放宽了规则,允许我们在使用引用时既能支持左值引用又能支持右值引用。但需要遵守下表的规则:
| 函数形参类型 | 实参参数类型 | 推导后函数形参类型 |
|---|---|---|
| T& | 左引用 | T& |
| T& | 右引用 | T& |
| T&& | 左引用 | T& |
| T&& | 右引用 | T&& |
完美转发就是基于上述规律产生的。所谓完美转发,就是为了让我们在传递参数的时候, 保持原来的参数类型(左引用保持左引用,右引用保持右引用)。完美转发使用的语法是std::forward<T>(t)。除了std::forward之外,还要注意要使用auto来对接完美转发实现正确的类型推导。
3.3 总结
本章作者没有提供测试题。
本章重点介绍了右值的引入带来一些需要注意的问题。此外还介绍了lambda表达式,以及使用std::function实现对函数的包装,使用std::bind实现函数和参数的绑定等。
4 教程第四章笔记:容器
原文本章的标题为“容器”。主要讲了一些modern c++中引入的新的container或者增强的container。
除了本教程提到的容器内容之外,建议同时参考微软关于容器的整体性描述.它将容器可以分为三个类别(序列容器、关联容器和容器适配器)去分别描述。
序列化容器包含vector,array,deque,forward_list,list等。要注意这五种容器的区别。容器类型选择通常应根据应用程序所需的搜索和插入的类型。 当对任何元素的随机访问超出限制并且仅要求在序列的末尾插入或删除元素时,vector应作为用于管理序列的首选容器。 当需要随机访问并且在序列起始处和末尾处插入和删除元素已到达极限时,应首选类deque容器进行操作。 当在序列内任何位置的高效插入和删除(采用常量时间)超出限制时,list容器的性能会很优异。 序列中间的此类操作需要元素副本和与序列中的元素数量成正比的分配(线性时间)。
关联性容器可分为两个子集:映射(map)和集合(set). 映射map,有时称为字典,包含键值对。键用于对序列排序,值与该键关联。map的无序版本是unordered_map。 集合set仅是按升序排列每个元素的容器,值也是键。 set的无序版本是unordered_set。map和set都仅允许将键或元素的一个实例插入容器中。 如果需要元素的多个实例,请使用multimap或multiset。 无序版本是unordered_multimap和unordered_multiset。 有序版本的映射和集合采用红黑树数据结构,而无序版本使用哈希表结构。
容器适配器是序列容器或关联容器的变体,为了简单明确起见,它对接口进行限制。 容器适配器不支持迭代器。queue容器遵循 FIFO(先进先出)语义。priority_queue是将最高值始终排在队列第一位的queue. stack容器遵循 LIFO(后进先出)语义。
4.1 std::array
std::array 对象的大小是固定的,如果容器大小是固定的,那么可以优先考虑使用 std::array 容器。std::array 容器的元素类型和大小都在编译期确定,因此可以避免运行时开销。
本章开头讲到了为什么要使用std::array. 其中提到了一点有趣的知识:由于 std::vector 是自动扩容的,当存入大量的数据后,并且对容器进行了删除操作, 容器并不会自动归还被删除元素相应的内存,这时候就需要手动运行 shrink_to_fit() 释放这部分内存。类似的例子如下:
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = { 1, 2, 3, 4, 5 };
std::cout << "Current capacity: " << vec.capacity() << std::endl; // Output: Current capacity: 5
vec.push_back(6); // 增加一个元素
std::cout << "After adding an element, capacity: " << vec.capacity() << std::endl; // Output: After adding an element, capacity: 10
vec.pop_back(); // 移除一个元素
std::cout << "After removing an element, capacity: " << vec.capacity() << std::endl; // Output: After removing an element, capacity: 10
vec.shrink_to_fit(); // 回收内存
std::cout << "After calling shrink_to_fit, capacity: " << vec.capacity() << std::endl; // Output: After calling shrink_to_fit, capacity: 5
vec.clear(); // 清空元素
std::cout << "After calling clear, capacity: " << vec.capacity() << std::endl; // Output: After calling clear, capacity: 5
vec.shrink_to_fit(); // 回收内存
std::cout << "After calling shrink_to_fit again, capacity: " << vec.capacity() << std::endl; // Output: After calling shrink_to_fit again, capacity: 0
return 0;
}
可以看出vector的内存个数并不是严格等于实际的元素数目。当移除一个或者清空vector时,它内部的空间并没有被回收,而是继续保留着,直到再次需要使用时才会重新分配内存。这就造成了内存的浪费。当需要回收内存时,需要使用shrink_to_fit()函数。
在讲完上面为什么不能直接使用std::vector,而引入了一个新的std::array之后。作者回答了为什么用std::array代替传统的数组。说是因为“使用 std::array 能够让代码变得更加’现代化’ ;而且封装了一些操作函数;同时还能够友好的使用标准库中的容器算法。”
请注意std::array的头文件是array。文中使用的std::sort函数在algorithm头文件中。关于std::array由几点要讲的:
- array的原型是
template<typename T, size_t N> class array. 其中T是元素类型,N是数组大小。 - 在需要和C风格的代码兼容时,可以通过array.data()会获取第一个元素的地址。或者通过array.front(), &array[0], &array.at(0)获取数组首地址。可通过array.size()获取数组大小。
- array有很多有用的成员函数,比如at(), back(), front(), data(), fill(), swap(), empty(), size(), max_size(), begin(), end(), rbegin(), rend(), cbegin(), cend(), crbegin(), crend()等。请注意front()和begin()的区别,以及back()和end()的区别。它们的返回类型不同。详情可查看microsoft关于array的介绍.
- array的元素类型和大小都在编译期确定,因此可以避免运行时开销。
4.2 std::list
原教程没有重点描述std::list, 因为这不是Modern C++新加入的容器。但是从内容完整性上我这里还是简单描述一下std::list.详细内容可阅读Microsoft关于std::list的介绍.
C++ 标准库列表类是序列容器的一个类模板,用于将它们的元素保持为线性排列,并允许在序列的任何位置高效插入和删除。 序列存储为双向链接的元素列表,每个包含一些 Type 类型的成员。它的原型是template <class Type, class Allocator= allocator<Type>> class list.
list的头文件是<list>.list提供了一系列功能函数以实现在随意位置插入和移除元素等操作以及一些必备的辅助操作。
4.3 std::forward_list
原教程简单介绍了std::forward_list, 但是没有深入讲解。std::forward_list是C++11引入的一种新的容器。和std::list的双向链表的实现不同,std::forward_list使用单向链表进行实现, 提供了 O(1) 复杂度的元素插入,不支持快速随机访问(这也是链表的特点),也是标准库容器中唯一一个不提供 size() 方法的容器。
std::forward_list的原型是template <class Type, class Allocator= allocator<Type>> class forward_list. 它的头文件是<forward_list>.它也提供了一系列插入的功能。因为采用了单向链表,所以它的操作相对没有list那么功能强大。但是它占用的资源更少。forward_list 提供了一种比 list 更轻量级、更高效的单向链表实现,适合对内存和性能有更高要求的场景。但在使用时需要注意迭代器失效的情况。
4.4 std::deque
原教程没有重点描述std::list, 因为这不是Modern C++新加入的容器。deque允许从队列的首尾两端进行元素的添加和删除。详情可参见Microsoft关于std::deque的介绍。
std::deque的原型是:template <class Type, class Allocator =allocator<Type>> class deque. 它的头文件是<deque>.
4.5 std::vector
原文教程没有对vector进行介绍。但是它非常重要,std::vector可能是我们平时最常用的容器。它的原型是template <class Type, class Allocator =allocator<Type>> class vector. 它的头文件是<vector>. vector以线性排列方式存储给定类型的元素,并允许快速随机访问任何元素。vector是需要力求保证访问性能时的首选序列容器。
4.6 无序容器map和set
传统 C++ 中的有序容器 std::map/std::set,这些元素内部通过红黑树进行实现, 插入和搜索的平均复杂度均为 O(log(size))。在插入元素时候,会根据 < 操作符比较元素大小并判断元素是否相同, 并选择合适的位置插入到容器中。当对这个容器中的元素进行遍历时,输出结果会按照 < 操作符的顺序来逐个遍历。而无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为 O(constant), 在不关心容器内部元素顺序时,能够获得显著的性能提升。C++11 引入了的两组无序容器分别是:std::unordered_map/std::unordered_multimap 和 std::unordered_set/std::unordered_multiset。
原教程的代码比较简洁。但是为了测试的有趣性,我自己编写了另一段代码。在我引入了随机数生成器,同时对比了有序和无序容器的性能。代码如下:
#include <iostream>
#include <map>
#include <unordered_map>
#include <set>
#include <unordered_set>
#include <string>
#include <random>
#include <chrono>
#include <array>
int main() {
std::mt19937 rng(std::random_device{}());
std::uniform_int_distribution<int> dis(1, 1000);
std::map<std::string, int> m;
std::set<int> s;
std::unordered_map<std::string, int> um;
std::unordered_set<int> us;
std::array<std::string, 10> str_arr;
std::array<int, 10> int_arr;
std::array <std::chrono::high_resolution_clock::time_point, 5> tim_arr;
for (int i = 0; i < 10; i++) {
int_arr[i] = dis(rng);
str_arr[i] = std::to_string(int_arr[i]);
}
tim_arr[0] = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10; i++) {
m.insert(std::make_pair(str_arr[i], int_arr[i]));
}
tim_arr[1] = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10; i++) {
um.insert(std::make_pair(str_arr[i], int_arr[i]));
}
tim_arr[2] = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10; i++) {
s.insert(int_arr[i]);
}
tim_arr[3] = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10; i++) {
us.insert(int_arr[i]);
}
tim_arr[4] = std::chrono::high_resolution_clock::now();
std::cout << "map insert operation spent "<< (tim_arr[1] - tim_arr[0]).count() << " nanoseconds" << std::endl;
std::cout << "unordered_map insert operation spent "<< (tim_arr[2] - tim_arr[1]).count() << " nanoseconds" << std::endl;
std::cout << "set insert operation spent "<< (tim_arr[3] - tim_arr[2]).count() << " nanoseconds" << std::endl;
std::cout << "unordered_set insert operation spent "<< (tim_arr[4] - tim_arr[3]).count() << " nanoseconds" << std::endl;
// show map
tim_arr[0] = std::chrono::high_resolution_clock::now();
std::cout << "map: " << std::endl;
for (const auto item : m) {
std::cout << "{" << item.first << ": " << item.second << "}, ";
}
std::cout << std::endl;
// show unordered_map
tim_arr[1] = std::chrono::high_resolution_clock::now();
std::cout << "unordered_map: " << std::endl;
for (const auto item : um) {
std::cout << "{" << item.first << ": " << item.second << "}, ";
}
std::cout << std::endl;
// show set
tim_arr[2] = std::chrono::high_resolution_clock::now();
std::cout << "set: " << std::endl;
for (const auto item : s) {
std::cout << item << ", ";
}
std::cout << std::endl;
// show unordered_set
tim_arr[3] = std::chrono::high_resolution_clock::now();
std::cout << "unordered_set: " << std::endl;
for (const auto item : us) {
std::cout << item << ", ";
}
std::cout << std::endl;
tim_arr[4] = std::chrono::high_resolution_clock::now();
std::cout << "map output operation spent " << (tim_arr[1] - tim_arr[0]).count() << " nanoseconds" << std::endl;
std::cout << "unordered_map output operation spent " << (tim_arr[2] - tim_arr[1]).count() << " nanoseconds" << std::endl;
std::cout << "set output operation spent " << (tim_arr[3] - tim_arr[2]).count() << " nanoseconds" << std::endl;
std::cout << "unordered_set output operation spent " << (tim_arr[4] - tim_arr[3]).count() << " nanoseconds" << std::endl;
return 0;
}
这段代码每次生成的结果是不同的,但是可以看出有序列表和无序列表的区别。比如某一次的输出如下:
map insert operation spent 10390 nanoseconds
unordered_map insert operation spent 6678 nanoseconds
set insert operation spent 2030 nanoseconds
unordered_set insert operation spent 2371 nanoseconds
map:
{308: 308}, {310: 310}, {45: 45}, {564: 564}, {619: 619}, {662: 662}, {757: 757}, {77: 77}, {948: 948}, {95: 95},
unordered_map:
{662: 662}, {564: 564}, {95: 95}, {310: 310}, {45: 45}, {308: 308}, {757: 757}, {948: 948}, {619: 619}, {77: 77},
set:
45, 77, 95, 308, 310, 564, 619, 662, 757, 948,
unordered_set:
619, 564, 95, 310, 308, 757, 45, 662, 948, 77,
map output operation spent 5049 nanoseconds
unordered_map output operation spent 13523 nanoseconds
set output operation spent 3034 nanoseconds
unordered_set output operation spent 2658 nanoseconds
因为我采用将打印的过程输出,所以所占用的时间并不等于将数据取出占用的时间。但是也具有一定的比较性。可以看到无序映射的插入速度比有序映射的插入速度块;但是无序映射的读出速度却比有序映射的读出速度慢。无序集合的插入速度却比有序集合的插入速度要慢,但是无序集合的读出速度要快。当然因为我插入的内容并不复杂,数量也不够规模化。如果要获得更精确的性能数据,可能需要更加复杂的测试。
4.7 元组
在传统C++,只有表示两个元素组成的键值对的pair,而没有像python那样支持多个元素的tuple。C++11中才引入了tuple。只是引入tuple之后并没有废弃pair。在map或者unordered map中,还是使用pair作为键值对的存储结构。常用的tuple函数有std::make_tuple()(用来构造元组), std::get<>()(用来获取元组中的元素), std::tie()(用来将多个变量绑定到元组中)。
但是这部分的难点是在介绍tupl运行时输入变量位置的方法中用到了std::varient。std::varient是C++17引入的新特性,用来解决函数模板的多态性。std::varient用于表示具有固定、有限数量的可能类型中的一个值。它类似于联合体(union),但是它提供了类型安全性保证,并且支持在运行时确定当前储存的是哪种类型。std::variant是一种类型安全的联合类型,能够容纳多种不同类型的值,但在任何给定时间,只有一个值是有效的。
#include <variant>
template <size_t n, typename... T>
constexpr std::variant<T...> _tuple_index(const std::tuple<T...>& tpl, size_t i) {
if constexpr (n >= sizeof...(T))
throw std::out_of_range("越界.");
if (i == n)
return std::variant<T...>{ std::in_place_index<n>, std::get<n>(tpl) };
return _tuple_index<(n < sizeof...(T)-1 ? n+1 : 0)>(tpl, i);
}
template <typename... T>
constexpr std::variant<T...> tuple_index(const std::tuple<T...>& tpl, size_t i) {
return _tuple_index<0>(tpl, i);
}
template <typename T0, typename ... Ts>
std::ostream & operator<< (std::ostream & s, std::variant<T0, Ts...> const & v) {
std::visit([&](auto && x){ s << x;}, v);
return s;
}
这段代码第一个模板函数_tuple_index用来递归的获取元组中的元素。第二个模板函数tuple_index用来调用_tuple_index,并将结果转换为std::variant。第三个模板函数operator«实现对cout的重载,实现对tuple的输出。这中间有几个复杂的用法。第一个是std::in_place_index<n>:std::in_place_index 是 C++17 引入的专门为 std::variant 设计的标签位,它的作用是指示 std::variant 要选择使用的类型。std::in_place_index带有一个参数n,表示要在variant的备选类型列表中第n个类型上就地构造。第二个是std::get<n>(tp1):std::get 是标准库中的函数模板,用于从元组中获取指定索引位置的值。它接受一个模板参数n,表示要获取的元素的索引位置。第三个是std::visit([&](auto && x){ s << x;}, v); : std::visit是C++17中引入的一个标准库函数,用于对std::variant中的值进行访问。它使用访问者模式,为std::variant中的每种可能的类型都提供了一个分支,可以根据实际存储的类型来调用对应的处理函数。
关于std::tuple最好的使用还是需要直到确定的参数数量。但对于可变参数数量的tuple,具体实现确实很复杂。需要使用std::tuple_size
4.8 总结
这部分讲了Modern C++新引入的容器类型。我在这部分顺便复习了三类容器:序列化容器,关联话容器和容器适配器。这部分原文还讲了元组,而且提供了可变参数元组的模板化实现方法。
这部分原书没有提供习题。
5 原书第五章内容笔记:智能指针与内存管理
原书的第五章标题是《智能指针与内存管理》. 通过标题你也应该直到这来到了Modern C++比较重要的一部分:智能指针。智能指针为Modern C++带来了更好的内存管理,也是多数Modern C++使用者比较青睐的功能。
在传统 C++ 里我们只好使用 new 和 delete 去 『记得』对资源进行释放。而 C++11 引入了智能指针的概念,使用了引用计数的想法,让程序员不再需要关心手动释放内存。 目前有三类智能指针,分别是std::shared_ptr, std::unique_ptr, std::weak_ptr。使用它们需要包含头文件
5.1 std::shared_ptr/公用指针
std::shared_ptr是一种智能指针,它能够记录多少个shared_ptr共同指向一个对象,从而消除显式的调用delete,当引用计数变为零的时候就会将对象自动删除。创建shared_ptr试用make_shared()函数,从而避免试用new来创建对象。 std::make_shared会分配创建传入参数中的对象, 并返回这个对象类型的std::shared_ptr指针。
std::shared_ptr可以通过get()函数来获取shared_ptr所指向的对象。通过use_count()函数来获取引用计数。通过reset()函数来重置shared_ptr,使其指向一个新的对象。
5.2 std::unique_ptr/独享指针
std::unique_ptr是一种独占的智能指针,它禁止其它智能指针与其共享同一个对象,从而保证代码的安全. 它只能被移动,不能被复制。创建std::unique_ptr需要使用std::make_unique()函数。
std::shared_ptrget()函数来获取shared_ptr所指向的对象。通过reset()函数来重置shared_ptr,使其指向一个新的对象。但是它不像std::shared_ptr有use_count()函数。实际测试发现可以将std::unique_ptrmove给一个std::shared_ptr对象。但是不能将一个std::shared_ptr赋值或者move给一个std::unique_ptr对象。
5.3 std::weak_ptr/弱指针
std::weak_ptr是一种弱引用(相比较而言 std::shared_ptr 就是一种强引用)。由于它是弱指针,因此它并不增加所指向对象的引用计数,也不阻止对象被释放。
- expired(): 该方法用于检查所指向的对象是否已经被释放。如果对象已经不再存在,返回 true;否则返回 false。
- lock(): 该方法返回一个
std::shared_ptr,指向与std::weak_ptr共享的对象.如果所指向的对象已经被释放,则返回一个nullptr。
原书并没有提供如何试用weak_ptr的例子。我对它提供的解释shared_ptr的代码做了适当的修改,提供了这样一个例子,可能更好的反应weak_ptr的用法。
#include <iostream>
#include <memory>
class A;
class B;
class A {
public:
std::weak_ptr<B> pointer;
~A() {
std::cout << "A was destroyed" << std::endl;
}
};
class B {
public:
std::weak_ptr<A> pointer;
~B() {
std::cout << "B was destroyed" << std::endl;
}
};
int main() {
std::shared_ptr<A> a = std::make_shared<A>();
{
std::shared_ptr<B> b = std::make_shared<B>();
a->pointer = b;
b->pointer = a;
std::cout << "a.use_count() = " << a.use_count() << std::endl;
std::cout << "b.use_count() = " << b.use_count() << std::endl;
if (a->pointer.expired()) {
std::cout << "1: a's pointer expired" << std::endl;
}
else {
std::cout << "1: a's pointer isn't expired" << std::endl;
}
}
if (a->pointer.expired()) {
std::cout << "2: a's pointer expired" << std::endl;
}
else {
std::cout << "2: a's pointer isn't expired" << std::endl;
}
return 0;
}
5.4 总结
智能指针这种技术并不新奇,在很多语言中都是一种常见的技术,现代 C++ 将这项技术引进,在一定程度上消除了 new/delete 的滥用,是一种更加成熟的编程范式。
本章没有提供习题。
6 原书第六章内容笔记:正则表达式
6.1 正则表达式
原教程对于正则表达式的描述还是很清楚的。正则表达式不是 C++ 语言的一部分。正则表达式描述了一种字符串匹配的模式,它是由普通字符(例如 a 到 z)以及特殊字符组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。一般使用正则表达式主要是实现下面三个需求:
- 是否包含:检查一个串是否包含某种形式的子串;
- 替换:将匹配的子串替换;
- 获取:从某个串中取出符合条件的子串。
文中还描写了普通字符,特殊字符和限定符。因为涉及的问题比较零碎,我就不再转述。我一般是借助一些网页工具帮助我辅助生成需要的正则表达式。因为要长时间记住这些字符确实比较困难,用的时候再了解即可。
6.2 std::regex 及其相关
传统C++没有将正则表达式正式纳入标准库,直到C++11才将其纳入其中。通过C++11 提供的正则表达式库可对std::string对象进行操作,模式std::regex(本质上是 std::basic_regex)由 std::regex_match 初始化并匹配生成 std::smatch(本质上是 std::match_results 对象。
-
std::regex_match用于匹配字符串和正则表达式,有很多不同的重载形式。 最简单的一个形式就是传入std::string以及一个std::regex进行匹配, 当匹配成功时,会返回 true,否则返回 false。 -
另一种常用的形式就是依次传入
std::string/std::smatch/std::regex三个参数, 其中std::smatch的本质其实是std::match_results。 故而在标准库的实现中,std::smatch被定义为了std::match_results<std::string::const_iterator>, 也就是一个子串迭代器类型的match_results。 使用std::smatch可以方便的对匹配的结果进行获取.
6.3 总结和习题
本章内容比较简单。但是结尾有一个习题。但是这个习题比较复杂,它没有提供需要填充的完整项目,需要自行下载配置。这个项目依赖与boost库的asio库。如果要顺利编程需要在运行环境中安装boost库。关于asio的使用,可以看这个教程
关于boost的安装这里简要交代一下。可以使用sudo apt search boost搜索,当前我的debian里面提供了1.81和1.74版本(默认)的安装。你可以使用如下命令安装:sudo apt install libboost-all-dev或者sudo apt install libboost1.81-all-dev.除了这种方法,你也可以从源码编译安装。具体可以查询boost的官方文档或者入门教程。安装boost会额外增加近500M的磁盘空间。此外asio实际上有两个子集,一个是boost的,另一个是non-boost的。
除了boost之外,这个库还需要安装openssl。请注意如果你只是通过sudo apt install openssl还不行,还需要安装sudo apt install libssl-dev.另外不同的boost库依赖的OpenSSL版本可能不同。
几个关于asio的教程:
7 原书第七章内容笔记:并行与并发
这是本书第七章,主要讲了并发和并行相关的一些技术。但是本书讲解的比较简单。如果想要了解完整的Modern C++关于并发技术的详情,可以看C++ Reference: Concurrency相关章节.
7.1 并行基础:thread
这部分简单介绍了thred的创建和等待。更详细的thread用法并没有介绍。另外提到了get_id()函数和join()函数。
如果想要稍微详细的了解thread,可以看这个教程和CPP Reference。
thread的原型:
thread() noexcept; // 创建一个默认构造函数
template <class Fn, class... Args>
explicit thread(Fn&& fn, Args&&... args); // 初始化构造函数,传入函数和参数
[deleted] thread(const thread&) = delete; // std::thread 对象不可拷贝构造
thread(thread&& x) noexcept; // moveable构造函数
总结起来可以为thread创建默认构造函数,或者创建时传入函数和参数。thread不能被copy但是可以被move。thread除了前面提到的用以获取thread id的get_id()和等待线程结束的join()函数实现外,还提供了其它函数:
- detach:
detach()方法用于将当前线程实体与该线程对象分离开来,使得线程的执行可以单独运行,这样分离出去的线程实体可以自行销毁而不需要调用join函数等待。k - joinable:
joinable()方法用于判断线程是否可以join,如果可以join,则返回true,否则返回false。 - swap:
swap()方法用于交换两个thread对象。这个其实不太容易想到场景。据说在一些复杂的线程管理和协作逻辑时可以用到swap. - yield:
yield()方法用于让出当前线程的执行权,让出时间片,让其他线程有机会执行。 - sleep_for:
sleep_for()函方法用于让当前线程暂停一段时间。 - sleep_until:
sleep_until()方法用于让当前线程暂停到指定的时间点。不过由于线程调度等原因,实际休眠时间可能比sleep_duration 所表示的时间片更长。 - native_handle:
native_handle()方法用于获取底层的线程句柄,可以用于一些底层的操作。(由于 std::thread 的实现和操作系统相关,因此该函数返回与 std::thread 具体实现相关的线程句柄,例如在符合 Posix 标准的平台下(如 Unix/Linux)是 Pthread 库)。
7.2 互斥量(Mutex)和临界区(Critical Section)
在将互斥量之前,先简单介绍一下临界区。临界区是指在多线程编程中一个同时只能被一个线程访问的代码块或者数据区域。在临界区内部的代码同一时刻只能被一个线程执行,这样可以避免多个线程同时访问共享资源而引发的数据竞争和不确定性行为。为了保护临界区不受并发访问的影响,通常使用同步机制来对临界区进行保护。常用的同步机制包括互斥锁(mutex)、信号量(semaphore)、条件变量等。在多线程编程中,正确使用临界区和合适的同步机制是确保数据完整性和避免竞态条件的关键。RTOS中的临界区概念和多线程临界区类似,只是需要更加关注调度和中断机制。
互斥量多多线程编程中经常用于解决资源竞争所使用的类型。C++11 引入了mutex相关的类,其所有相关的函数都放在<mutex>头文件中。mutex的函数比较简单,主要有:
- lock:
lock()方法是阻止调用线程,直到线程获取互斥体的所有权。 - try_lock:
try_lock()方法用于尝试锁住互斥量,如果互斥量已经被其他线程锁住,则返回false,否则返回true。 - unlock:
unlock()方法用于解锁互斥量,使得其他线程可以访问临界区。 - native_handle:
native_handle()方法返回表示mutex句柄的特定于实现的类型。可以特定于实现的方式使用互斥体句柄。
如果想要更加清晰的了解标准库里的mutex,可以看微软关于mutex的文档。
C++11 还为互斥量提供了一个 RAII 语法的模板类 std::lock_guard。 RAII 在不失代码简洁性的同时,很好的保证了代码的异常安全性。由于 C++ 保证了所有栈对象在生命周期结束时会被销毁,所以这样的代码也是异常安全的。 无论 critical_section() 正常返回、还是在中途抛出异常,都会引发堆栈回退,也就自动调用了 unlock()。lock_guard的使用比较简单,详情可以查看微软关于lockguard的文档。
而std::unique_lock则是相对于std::lock_guard出现的,std::unique_lock更加灵活,std::unique_lock的对象会以独占所有权(没有其他的unique_lock对象同时拥有某个 mutex对象的所有权) 的方式管理mutex对象上的上锁和解锁的操作。所以在并发编程中,推荐使用 std::unique_lock。std::lock_guard 不能显式的调用 lock 和 unlock, 而 std::unique_lock 可以在声明后的任意位置调用,可以缩小锁的作用范围,提供更高的并发度。unique_lock还可以wait条件变量,总之它更加灵活强大。std::unique_lock提供了多个方法:lock, try_lock, try_lock_for, try_lock_until, unlock, swap, release, owns_lock。这里不再一一转述。详情可以查看微软关于uniquelock的文档。
7.3 Future/Promise/Async 期物/承诺/异步
原文将Future翻译成“期物”。涉及到Future的另外两个概念,这一章尽管没有描述但我觉得有必要交代。这两个概念时Promise翻译成“承诺”,Async翻译成“异步”。这三个概念在并发编程中都有重要的作用。关于这三者的联系后续应该自然会讲到。这里是三个概念和packaged_task的的详细介绍。
- CPP Reference: std::future
- CPP Reference: std::promise
- CPP Reference: std::async
- CPP Reference: std::packaged_task
std::future的使用很大程度上优化了异步获取数据的实现。原文对其解释的还是不错的。文中在介绍时还提到了std::packaged_task。只是文中对于Future的介绍非常的简单。建议看我上面提供的链接详细了解一下这些概念。Future一般是通过std::promise,std::async或std::packaged_task等异步操作来创建的。Future的状态有三种:
- 等待(Waiting):Future对象刚刚被创建,或者刚刚被设置值。
- 就绪(Ready):Future对象已经被设置值,可以获取值。
- 已完成(Done):Future对象已经完成,不能再设置值。
Future的获取值有两种方式:
get():阻塞等待Future对象的值,直到值可用。wait():非阻塞等待Future对象的值,如果Future对象的值已经可用,则立即返回,否则阻塞等待。wait_for():等待Future对象的值,直到超时或Future对象的值可用。wait_until():等待Future对象的值,直到指定的时间点或Future对象的值可用。
Future只要通过std::promise,std::async或std::packaged_task等来get_future()的。因此有必要简单介绍一下这三者。
7.3.1 std::promise (承诺/约定)
promise和Future配合使用,以实现异步编程。promise是一个承诺,它代表了一个将要被设置值的对象。需要注意promise只能设置一次值,设置值后,promise就变成了不可设置的对象。promise的创建需要用到std::promise类。它的原型如下:
template< class R > class promise; // 基础模板
template< class R > class promise<R&>; // 非void专用模板,用于线程通讯
template<> class promise<void>; // void专用模板
每个promise都有一个共享状态(shared state),共享状态包含了状态和结果。结果可能是“尚未求值”,“已经获取值”(可以是void),或者“异常”。promise的函数有:
get_future():返回一个Future对象,该对象代表了promise的共享状态。set_value():用来将特定值(value)设置给结果。set_value_at_thread_exit():用来在线程退出时设置结果。set_exception():设置结果为某个异常状态。因此要注意Future在获取值时,安全期间或使用try-catch块来捕获异常。set_exception_at_thread_exit():设置结果为某个异常状态,并且在线程退出时设置。swap():交换两个promise对象。
7.3.2 std::async (异步)
async负责异步运行一个函数(可能在新线程中),并返回一个std::future去保存结果。async的原型如下:
// 基础模板, 在C++11~C++17之间可以用,随后被另一种实现取代
template< class F, class... Args >
std::future<typename std::result_of<typename std::decay<F>::type(
typename std::decay<Args>::type...)>::type>
async( F&& f, Args&&... args );
// 基础模板, 在C++17到C++20之间被使用,取代了前一种实现
template< class F, class... Args >
std::future<std::invoke_result_t<std::decay_t<F>,
std::decay_t<Args>...>>
async( F&& f, Args&&... args );
// 基础模板, 在C++20之后被使用,取代了前两种实现
template< class F, class... Args >
[[nodiscard]] std::future<std::invoke_result_t<std::decay_t<F>,
std::decay_t<Args>...>>
async( F&& f, Args&&... args );
// 带有策略参数的模板,用于指定线程创建策略
// 在C++11~C++17之间可以用,随后被后一种实现取代
template< class F, class... Args >
std::future<typename std::result_of<typename std::decay<F>::type(
typename std::decay<Args>::type...)>::type>
async( std::launch policy, F&& f, Args&&... args );
// 带有策略参数的模板,用于指定线程创建策略
// 在C++17~C++20之间可以用,随后被后一种实现取代
template< class F, class... Args >
std::future<std::invoke_result_t<std::decay_t<F>,
std::decay_t<Args>...>>
async( std::launch policy, F&& f, Args&&... args );
// 带有策略参数的模板,用于指定线程创建策略
// 在C++20之后被使用,取代了前两种实现
template< class F, class... Args >
[[nodiscard]] std::future<std::invoke_result_t<std::decay_t<F>,
std::decay_t<Args>...>>
async( std::launch policy, F&& f, Args&&... args );
上面的原型看似复杂,但对于用户实际上只有两种参数形式:一种带函数和参数,另一种还携带了策略参数。策略参数用于指定线程创建策略,可以是std::launch::deferred或std::launch::async。std::launch::deferred表示延迟创建线程,直到调用std::future::get()时才创建线程。std::launch::async表示立即创建线程。
有一点请注意,std::async的返回值是一个std::future,但这个future的类型是由函数的返回值决定的。它不像promise那样可以需要通过get_future()去获取一个future对象。
7.3.3 std::packaged_task (打包任务)
packaged_task是一个包装器,它可以用来存储一个可调用对象(callable object,包括function, lambda表达式, bind表达式, 或任何函数对象),并将其提交给线程池。包装器的创建需要用到std::packaged_task类。它的原型如下:
// 基础模板
template< class > class packaged_task;
// 带参数模板
template< class R, class ...ArgTypes >
class packaged_task<R(ArgTypes...)>;
packaged_task的函数有:
get_future():返回一个Future对象,该对象代表了packaged_task的共享状态。make_ready_at_thread_exit():在线程退出时设置结果。swap():交换两个packaged_task对象。valid():判断packaged_task对象是否有效。operator():调用packaged_task对象所包装的可调用对象。reset():重置packaged_task对象,使其可以被重新使用。
最后需要提一句的是,请注意在packaged_task传递的时候传递时都使用的是std::move。谨记。
7.4 condition variable(条件变量)
std::condition_variable 是与 std::mutex 配合使用的同步原语,用于阻塞一个或多个线程,直到另一个线程修改了共享变量(条件)并通知了 std::condition_variable。
condition_variable有两个版本。condition_variable仅适用于 std::unique_lock<std::mutex>,这样可以在某些平台上实现最高效率。std::condition_variable_any 提供了一个适用于任何BasicLockable对象(如std::shared_lock)的条件变量。
条件变量允许同时调用 wait、wait_for、wait_until、notify_one 和 notify_all 成员函数。
原文对于condition_variable的介绍和演示没有涉及到wait的pred条件部分。建议看cpp reference: std::condition_variable.另外在搜索网络资源时,看到一款还不错的文章条件变量condition_variable的使用及陷阱。
要理解condition variable,可以认为它的wait函数负责自动解锁,等待,验证和自动加锁的一段自动处理流程。
7.5 内存模型和原子操作(atomic)
原文介绍了在多线程中原子操作的必要性。但是原文对std::atomic的介绍并不详细。建议看cpp reference: std::atomic。
std::atomic的原型是:
template< class T >
struct atomic;
// (1) (since C++11)
template< class U >
struct atomic<U*>;
// (2) (since C++11)
// Defined in header <memory>
template< class U >
struct atomic<std::shared_ptr<U>>;
// (3) (since C++20)
template< class U >
struct atomic<std::weak_ptr<U>>;
//(4) (since C++20)
// Defined in header <stdatomic.h>
#define _Atomic(T) /* see below */
// (5) (since C++23)
下面是std::atomic的几个重要函数:
is_lock_free函数可以用来检查该原子类型是否是无锁的。(原文描述有误,详情可参见这里)is_always_lock_free函数可以用来检查该原子类型是否是始终无锁的。store函数用来给atomic赋值load函数用来读取atomic的值exchange函数用来交换值wait函数用来等待条件变量notify_one函数用来通知一个等待线程notify_all函数用来通知所有等待线程
某些基础类型还支持如下操作:
fetch_add函数用来原子地加减。等价符号可以是++或+=操作。fetch_sub函数用来原子地加减。等价符号可以是--或-=操作。fetch_and函数用来原子地与。等价符号是&=操作。fetch_or函数用来原子地或。等价符号是|=操作。fetch_xor函数用来原子地异或。等价符号是^=操作。
对于modern c,也引入了_Atomic。_Atomic is a keyword and used to provide atomic types in C. 在c语言中_Atomic是为c语言提供原子类型的关键字,基本功能和c++中的std::atomic类似。在gcc或者clang中某些功能可能需要添加链接条件-latomic.
这里再探讨一下是否支持无锁操作的问题:
All atomic types except for std::atomic_flag may be implemented using mutexes or other locking operations, rather than using the lock-free atomic CPU instructions. Atomic types are also allowed to be sometimes lock-free, e.g. if only aligned memory accesses are naturally atomic on a given architecture, misaligned objects of the same type have to use locks.
除了std::atomic_flag之外,所有原子类型都可以使用互斥或其他加锁操作来实现,而不是使用无锁的 CPU 原子指令。原子类型有时也允许是无锁的,例如,如果在给定的体系结构上只有对齐的内存访问是天然原子的,那么同一类型的错位对象就必须使用锁。
The C++ standard recommends (but does not require) that lock-free atomic operations are also address-free, that is, suitable for communication between processes using shared memory.
C++ 标准建议(但不要求)无锁原子操作也是无地址的,也就是说,适用于使用共享内存的进程之间的通信。
除了std::atomic,还有一个经常用到的原子操作是std::atomic_flag。std::atomic_flag是一个原子类型,可以用来实现简单的互斥。它的原型如下:
class atomic_flag {
public:
atomic_flag() noexcept;
atomic_flag(const atomic_flag&) = delete;
atomic_flag& operator=(const atomic_flag&) = delete;
void clear() noexcept;
bool test_and_set() noexcept;
};
请注意std::atomic_flag和std::atomic
原文中还讨论了一致性模型。在这之前我并未意识到有这么多一致性模型的。它们分别是线性一致性(强一致性或者原子一致性),顺序一致性,因果一致性和最终一致性(有界一致性)。这些不同的一致性需求就引入了内存顺序的概念。
C++11还提供了std::memory_order,用于描述内存模型。std::memory_order有六种模型:
- memory_order_relaxed: 宽松模型。此模型只要求在单个线程内原子操作顺序执行。不允许指令重排,但不同线程间原子操作的顺序是任意的。
- memory_order_release/memory_order_consume: 发布/消费模型。在此模型下消费者会对发布(release)的原子操作进行读取。消费者依赖于发布者release时的值。
- memory_order_release/memory_order_acquire: 发布/获取模型。在此模型下,在释放 std::memory_order_release 和获取 std::memory_order_acquire 之间规定时序,即发生在释放(release)操作之前的所有写操作,对其他线程的任何获取(acquire)操作都是可见的,亦即发生顺序(happens-before)。
- memory_oder_seq_cst: 顺序一致性模型。在此模型下,所有线程的原子操作都按顺序执行,并且在其他线程的原子操作之前完成。
除了上面用到的5种内存模型,还有一个memory_order_acq_rel模型,它是memory_order_acquire和memory_order_release的组合。它表示在释放和获取之间的所有操作都必须是原子的。一般用于std::compare_exchange_weak和std::compare_exchange_strong中。(因为这个操作的过程中既需要要确保在它之前的写入操作和在它之后的读出操作都被更新。)
关于内存模型的文章可以看cpp reference: Memory Model.
7.6 jthread(C++20)
这一部分是额外增加的内容。用来介绍C++20引入的jthread。jthread是C++20引入的新线程类型,可以用来简化线程创建和管理。jthread是jionable thread的缩写。关于jthread的详细介绍,可以看C++ Reference: std::jthread。
jthread的创建需要用到std::jthread类。它的原型如下:
template<class F, class... Args>
std::jthread(F&& f, Args&&... args);
jthread的特殊之处在于它创建的线程在运行后会自动被join。这样会避免因为用户失误导致的线程泄漏问题。而且jthread还提供了几个额外的函数可以确保线程可以被停止。这些函数是:
request_stop():请求停止线程。join: 等待线程结束。detach: 解除线程与其创建者的关联。swap: 交换两个jthread对象。
7.7 std::atomic_thread_fence (C++20)
内存屏障在前面简单介绍过。但是那些主要时在atomic中使用的内存序。但是atomic_thread_fence可以提供更高级的内存屏障。具体内容可以查看cpp reference: std::atomic_thread_fence.
为什么需要atomic_thread_fence? 因为atomic的内存顺序只能保证这个atomic变量的内存序,不能保证多个不同变量的操作顺序。
7.8 总结和习题
本章主要讲了并发编程相关的一些类型。这里不在一一列举。modern c++标准库中定义的这些类型可以方便再不同平台之间移植。比单纯的使用linux下的pthread库要更加安全和易用。
本章的习题主要是对上述内容的巩固和复习。
除了本章现有的内容。若想要了解更过modern C++并发编程相关内容,可以参考B站现代C++并发编程教程和另一篇modern c++并发编程教程.
习题说明:
习题1:请编写一个简单的线程池,提供如下功能:
ThreadPool p(4); // 指定四个工作线程
// 将任务在池中入队,并返回一个 std::future
auto f = pool.enqueue([](int life) {
return meaning;
}, 42);
// 从 future 中获得执行结果
std::cout << f.get() << std::endl;
回答:这里你需要知道线程池的基本概念。线程池是一种线程管理技术,它可以用来管理线程的创建和销毁,并提供一个线程池来执行任务。线程池的基本原理是:创建指定数量的线程,并将任务放入队列中。当有空闲线程时,线程池会从队列中取出任务并执行。当所有的线程都在执行任务时,线程池会等待。线程池可以有效地避免资源竞争,提高程序的并发度。线程池顾名思义是使用池化的思想处理任务。比方有一一组任务需要依次执行,但是我们并行处理的任务能力有限(因为硬件资源有限,同时开启太多个线程可能反而会降低系统的性能。)一种方式就是将需要执行的任务排队执行。一个任务执行完毕就将其移除队列,然后从队列中取出任务继续执行。直到所有任务都执行完毕,便进行对待。当需要销毁线程池时再将线程全部销毁。
对不不熟悉线程池的人来说,这个question的难度可能会比较大。建议先阅读一下一个基于现代C++简单线程池的实现。当然这篇文章没有实现对返回值的观察(std::future)。有一个广受欢迎的库vit-vit/CTPL. wikipedia对线程池也有介绍。另外还有科研人员提供一个基于C++17的线程库研究论文,它开源的项目在这里bshoshany/thread-pool。
习题2:请使用 std::atomic 实现一个互斥锁
这个问题我想的比较简单。但是作者的解答用到了内存屏障。看起来我对这部分的理解还是很浅薄。
除了使用std::atomic